
Как собрать отчет в Yandex DataLens быстро и почти просто
Google Data Studio это, конечно, хорошо, но у нас есть свой чудесный аналог — похожий инструмент от одной из передовых ИТ-компаний РФ Yandex Datalens. Сегодня в паре абзацев попробуем быстро собрать отчет, аналогичный материалу про Data Studio. Спойлер: это не так просто, как кажется на первый взгляд. Но давайте разбираться.
Первые шаги:
Первое и самое главное — я действительно очень уважаю компанию Яндекс и с интересом слежу за всем, что происходит в их открытых каналах. Но по части построение интерфейсов и справочной документации у меня иногда возникает ощущение перегруженности. С дизайном все ок, никаких проблем, и даже первые экраны работы с чем-либо просты и понятны. Но как только ты начинаешь углубляться в функции инструмента появляется все больше вопросов. Даже поиск по справке работает не совсем так, как хотелось бы — ответы на некоторые вопросы я нашел при чтении доки, но не нашел поиском. Хотя, может, и нашел бы, но кто его знает, содержимое второго экрана/второй страницы поиска.
Настройка источника
Выбор тут несколько скромнее, чем в Data Studio, но в то же время более, чем достаточен для большинства проектов.

В нашем случае БД всё та же MySQL, настройки всё такие же, только работать мы будем только в нормированными данными — никаких гипотез об их чистоте строить уже нет необходимости.
После настройки подключения у меня возник когнитивный диссонанс: попасть в главное меню оказалось не так уж просто. При том, что интерфейс не кажется таким уж перегруженным кнопками, столкнуться с подобной проблемой я никак не рассчитывал. Забегая вперед — мне пришлось ещё и импортировать мускульное представление в CSV и добавить ещё и его как источник. Зачем — дальше по тексту.
Но на этом сложности в моей картине мира не закончились. Допустим, я хочу собрать какой-то новый лист с информацией. В Data Studio фигурировало максимально понятное для меня понятие “отчета”. Здесь вроде как тоже есть дашборд, но тогда за что отвечают чарты и датасеты?
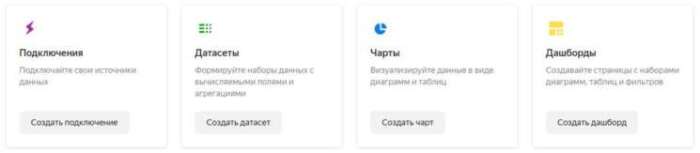
Датасеты
Раздел “Датасеты” — это слой трансформации (пусть и весьма упрощенной) в нашем ETL-механизме. Я не нашел именно этого механизма в Дата студии. То есть, какие-то манипуляции с полями-то вы можете произвести, но уже внутри отчета, что не совсем ложится в ETL. Яндекс пошел по значительно более логичному (лично для меня) пути, в то время как Google заставляет вас качественно готовить витрины для BI-решений. Окей, это тоже подход, но за гибкость решения Даталенс однозначно получает плюс в карму.
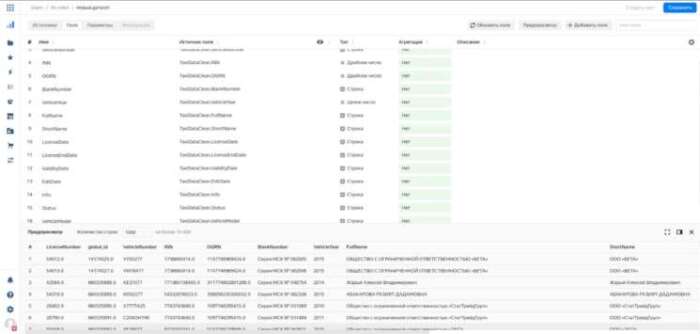
Какие типы данных
Данный слой позволяет нам из сырых данных собрать условно новую витрину, которая может являться агрегатом исходных данных. Какие же возможности у нас есть? Для начала разберемся с типами данных, которые воспринимает Даталенс:
“Геополигон”. Внутренняя история про карты, подробностей пока рассказать не могу.
“Геоточка”. То же самое, что и выше, только конкретная координата в пространстве.
“Дата” и “Дата и время”. Отличия очевидны, только вот автоматически парсер не смог понять, что 17.06.2015 — это дата. Странно и не очевидно, но допустим. Вручную поменять можно, но как централизованно объяснить Ленсу, что дата лежит в таком-то формате мне не удалось.
“Дробное число”. Вот тут надо быть аккуратным, поскольку в дробное может попасть и id, и год, и даже ИНН.
“Целое число”. Тут, думаю, всё понятно и все-таки стоило бы именно его сделать числовым параметром по умолчанию. Вижу цифры — думаю, что целое.
“Логический”, то есть булево true/false.
“Строка”. Второй по популярности после дроби тип данных по мнению Даталенса. Что ж, примерно так оно и есть, и лучше бы ИНН (который, кстати, вполне себе стандартизирован) тоже определялся сразу как строка.
Что можно сделать
В случае со строкой можно посчитать общее значение для поля или количество уникальных значений, короче count и count distinct. В случае с числами всё то же самое плюс максимум, минимум, среднее и сумма. Дата аналогично, но, разумеется, нет суммы. Ну а у булевых данных мы можем только количество посчитать, что тоже вполне логично.
А вот если вы захотите создать новое поле, вам на выбор будет доступно большое количество функций. Названия их специфичны, одновременно и похожи на что-то, и не похожи ни на что. Возможно, где-то в Кликхаусе есть подобный синтаксис или в одной из разновидностей SQL. Функций не так много, справочник небольшой и мне чем-то болезненно напоминает справочник по QlikView/Sense.
Без использования этих функций нам не построить ничего, поскольку формирование нового поля — единственный способ объяснить парсеру, в каком формате у нас лежит дата (если он сам с ходу этого не понял). Причем используемая для этого функция DATETIME_PARSE спокойненько определит формат даты без вашего участия, главное её в-принципе использовать. Что мешает по умолчанию применять её для всех полей формата “дата” для меня остается загадкой.
Хотя я поторопился с тем, что эта функция решит все наши проблемы. Дело в том, что не все функции могут работать со всеми источниками в настройке датасета. Как это работает? Если данные лежат в КликХаусе — у вас всё в порядке, вы можете особо ни за что не переживать. Если данные лежат в какой-либо ещё СУБД — вам необходимо смотреть документацию и проверять, работает ли та или иная функция с вашим источником. Сначала я не понял в чем дело, а потом понял: ДатаЛенс применяет все преобразования буквально на лету. Правда, чем одно и то же значение поля отличается в разных СУБД, а главное почему с CSV всё работает прекрасно я так и не понял. Более того, у полей, где дата указана в более-менее традиционном виде ГГГГ-ММ-ДД тип поля вполне себе подтянулся автоматически. Но собрать в тип даты указание просто года не выйдет никак.
Построение чартов
Казалось бы, а зачем вообще нужны чарты, если все визуализации можно делать напрямую в дашбордах? Скорее всего это связано с возможностью один чарт поместить сразу в несколько дашей, правда на практике я с такой потребностью сталкиваюсь не часто: обычно приходится все-таки что-то кастомизировать.
Но не всё так просто и однозначно, ведь помимо классического понимания чартов есть т.н. QL-чарты. Это объекты, которые строятся напрямую из источника (в данном случае речь о БД). Поработать с ними планирую в другой раз.
Чарт “Столбчатая диаграмма”
Для того, чтобы корректно работать с чартами, необходимо создать вычисляемые поля — показатели. Делается это в левой части экрана щелчком по пиктограмме “+”:
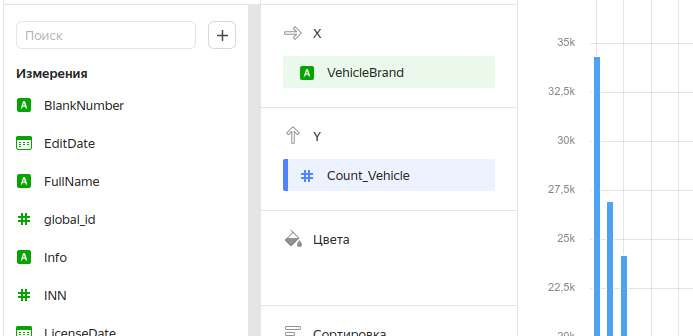
Показатели также работают с формулами, примерно с теми же, что и поля в построении датасета. Мне удалось использовать расчеты в формировании чарта и без создания отдельных показателей, но это костыли, которые работают только через drag-n-drop.
Интересный момент касается отображения ТОП-n позиций. Для этого необходимо создать показатель с формулой “rank(Поле)”, которое будет ранжировать поле, потом поставить его в фильтры и выбрать меньше либо равно (или просто меньше) требуемого числа. Не слишком прозрачная схема, не так ли?
Показатели также работают с формулами, примерно с теми же, что и поля в построении датасета. Мне удалось использовать расчеты в формировании чарта и без создания отдельных показателей, но это костыли, которые работают только через drag-n-drop.
Интересный момент касается отображения ТОП-n позиций. Для этого необходимо создать показатель с формулой “rank(Поле)”, которое будет ранжировать поле, потом поставить его в фильтры и выбрать меньше либо равно (или просто меньше) требуемого числа. Не слишком прозрачная схема, не так ли?
Чарт “Таблица”
В случае с таблицей всё довольно просто: в качестве столбцов указываем все интересующие нас поля (в нашем случае их 4), фильтры и прочие радости на свой вкус и цвет.
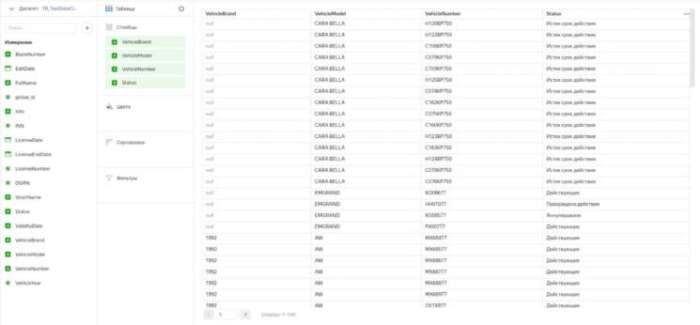
Настройки таблицы при этом довольно скудные:
В случае с таблицей всё довольно просто: в качестве столбцов указываем все интересующие нас поля (в нашем случае их 4), фильтры и прочие радости на свой вкус и цвет.
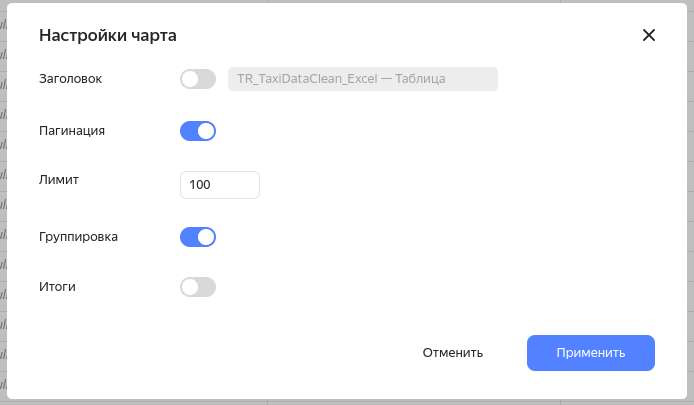 Чарт “Индикатор”
Чарт “Индикатор”
Здесь тоже все довольно просто, поскольку имеет какой-то минимум настроек. Мне не совсем понятно, что помешало ребятам прикрутить выбор кегля шрифта, а не размерную сетку футболок (XL, L, M — ну вы поняли).
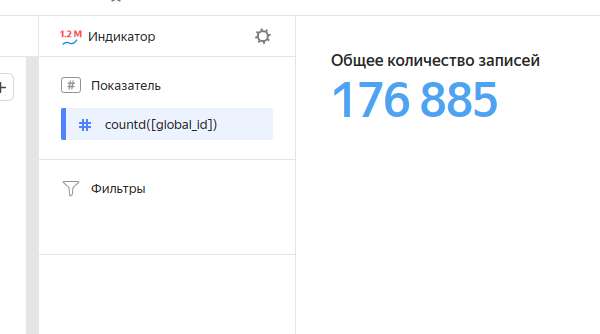
Можно не создавать отдельно вычисляемое поле, а посчитать всё в рамках чарта — скорее всего это будет удобнее для ваших целей.
Построение Дашборда:
Честно говоря, как только я зашел в этот раздел, я немного оторопел. Несколько странно и непривычно видеть абсолютно пустой белый лист даже без кнопочек управления. С другой стороны, кому-то вид белого листа может наоборот показаться притягательным.

Ладно, понятно, что там есть кнопка “добавить”, но UI все-таки выглядит недоработанным по сравнению с мэтрами или тем же Data Studio. Ладно, попробуем добавить элемент, может быть что-то станет понятнее… Нет. На выбор есть аж 4 варианта: чарт, селектор, текст и заголовок. Не то, чтобы я сходу мог придумать что-то чего мне не хватает… А, нет, смог — изображения например.
Пробуем добавить заголовок и выясняем несколько особенностей: менять размер блока можно только потянув за правый нижний угол, скорректировать размер текста можно только по 4 градациям large -> xsmall, управлять отступами текста нельзя вообще. Есть некоторые вопросы к подобному юзабилити. А как же пиксель перфект?
Настройки добавления чартов чартов довольно просты и не требуют пояснений:
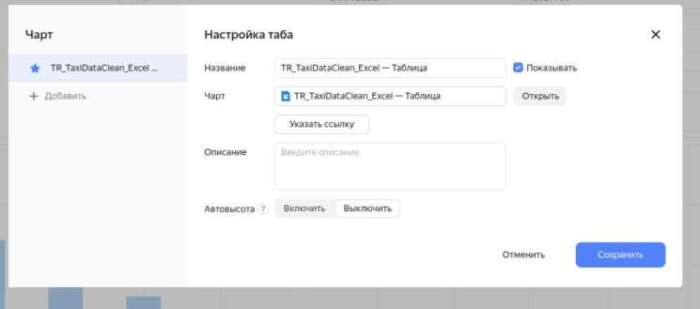
Почему именно “автовысота” не до конца понятно, почему тогда вообще не автомасштабирование, но допустим.
Добавление фильтров, которые вовсе не фильтры, а “селекторы”, тоже простое и логичное:
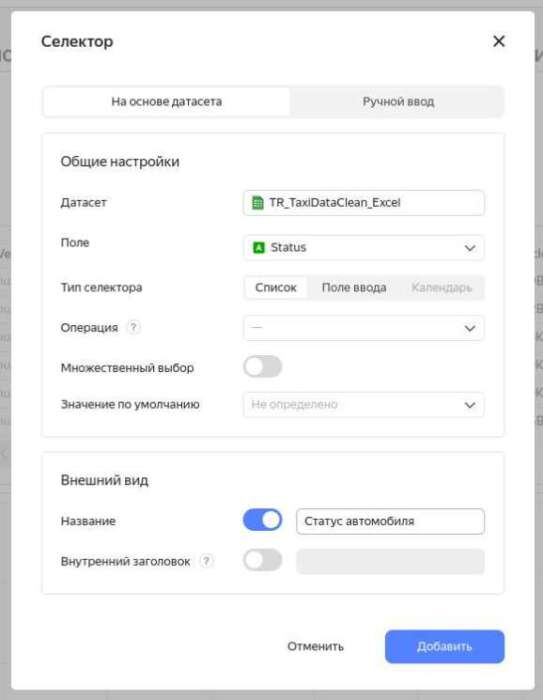
А вот с расположением объектов какая-то оказия. Объекты липнут только к определенным областям, и, к примеру, расположить фильтры левее показателя “тотала” по записям у меня не вышло. Возможно чуть позже стоит поковырять сетку, чтобы хотя бы для себя понять причины такого поведения объектов.
Собрав всё воедино, получаем следующую картину:
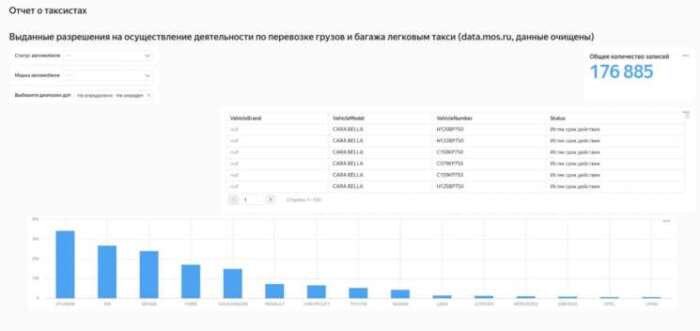
Резюме:
Из этого лонгрида может сложиться впечатление, что меня не устроил DataLens или что я в нем не слишком-то разобрался. Это не так. Ребята из Яндекса даже сделали хорошую болталку в TG, посвященную этому продукту, и эксперты в ней довольно быстро решают тот или иной вопрос. Кроме тех, конечно, которые на данном этапе решить просто нельзя.
Продукт хорошо подойдет для базовой аналитики. В нем можно создавать довольно сложные формулы, интересные визуализации — но не всегда это получается сделать логично, то есть так, как это годами делалось в аналогичных решениях. В то же время некоторая обрезанность ресурсов-источников вызывает просто недоумение: зачем мне мигрироваться в Яндекс.Облако только для того, чтобы даты стали датами?
Возможности кастомизации визуала я пока также до конца не раскусил: их либо толком и нет, либо так мало, что и говорить об этом бессмысленно. Хотя так ли их много у Google Data Studio?!
Я надеюсь, что проект будет развиваться семимильными шагами, о нем будет узнавать все больше людей, а сам Яндекс будет прислушиваться к пользователям и внедрять всё то, чего так не хватает сейчас. Мне же удалось выполнить то, что я задумал — я получил результат, аналогичный сервису от Google. И местами это было даже проще — но только местами.